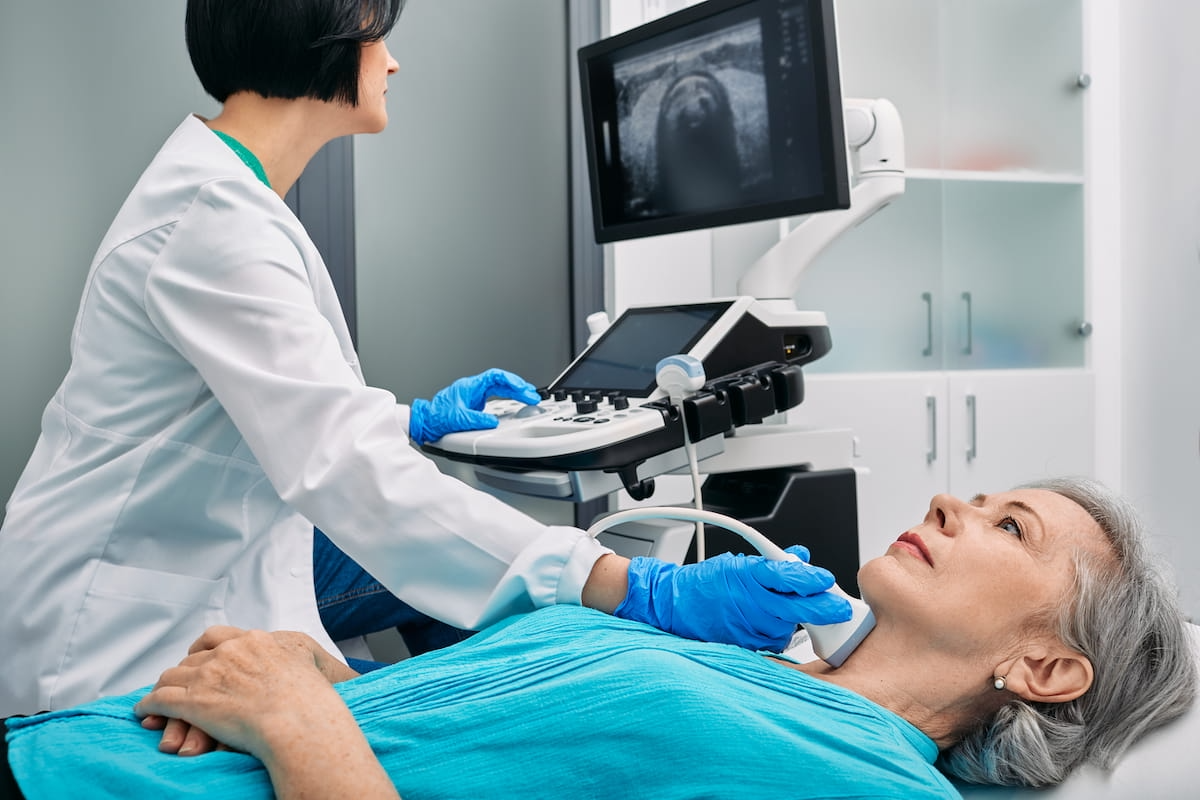
Emerging ultrasound (US) research suggests the integration of large language models (LLMs), such as ChatGPT 4.0, with image-to-text interpretation may offer comparable assessment to the combination of radiologists and LLMs in diagnosing thyroid nodules.
For the retrospective study, recently published in Radiology, researchers compared ChatGPT 3.5 (OpenAI), ChatGPT 4.0 (OpenAI) and Gemini (Formerly known as Bard, Google) in the assessment of thyroid nodules on 1,161 ultrasound images from a total of 725 patients (mean of 42.2 years). The study authors also compared LLM performance with image-to-text interpretation, a combination of LLM and human assessment (Human-LLM), and a convolutional neural network (CNN) analysis, which was trained on over 18,000 images.
For the image-to-text approach, the researchers noted a 79 percent intra-LLM agreement for Gemini, which was 8 percent higher than ChatGPT 4.0 (71 percent) and 30 percent higher than ChatGPT 3.5 (49 percent). The study authors also pointed out a 75 percent inter-LLM agreement on image-to-text interpretation between Gemini and ChatGPT 4.0.
For predicting benign versus malignant thyroid nodules on ultrasound, Gemini and ChatGPT had comparable AUCs for image-to-text interpretation and human-LLM assessments by the four reviewing radiologists, according to the study. However, the researchers noted differences between the two LLMs with respect to sensitivity and specificity rates.
With the image-to-text approach, ChatGPT 4.0 offered a 95 percent sensitivity rate in comparison to 87 percent for Gemini. In the Human-LLM interaction model, the use of ChatGPT led to 12 percent, 17 percent, and 7 percent higher sensitivity for three of the four readers (two junior radiologists and one senior radiologist) in comparison to Gemini. However, the researchers said the use of Gemini resulted in higher specificity for image-to-text assessment (75 percent vs. 71 percent) and for human-LLM interactions for all readers (including a 12 percent increase for one junior radiologist).
“This study affirms — to our knowledge for the first time — the feasibility of LLMs in handling the reasoning questions associated with medical diagnosis using the reference standard of pathologic findings within the structured domain of US imaging–based diagnosis,” wrote senior author Wei Wang, M.D., Ph.D., who is affiliated with the Department of Medical Ultrasonics and the Ultrasomics Artificial Intelligence X-Laboratory within the Institute of Diagnostic and Interventional Ultrasound at the First Affiliated Hospital of Sun Yat-Sen University in Guangzhou, China, and colleagues.
The study authors emphasized that LLMs are dependent upon human interpretation. While the researchers found image-to-text interpretation with LLMs was either generally comparable or higher than that of a human-LLM combination approach, they noted that one senior reader had four percent higher AUC, accuracy, sensitivity, and specificity rates with LLM in comparison to image-to-text interpretation with Gemini.
“This emphasizes the ongoing indispensable role of human expertise, despite artificial intelligence advances in medical imaging and diagnostics,” added Wang and colleagues.
Three Key Takeaways
- Comparative performance. The study indicates that large language models (LLMs), specifically ChatGPT 4.0 and Gemini, integrated with image-to-text interpretation show comparable performance to the combination of radiologists and LLMs in diagnosing thyroid nodules on ultrasound. This suggests that LLMs can play a significant role in medical image interpretation, potentially reducing the need for a combined assessment involving human experts.
- Sensitivity and specificity differences. While Gemini and ChatGPT demonstrated comparable area under the curve (AUC) for predicting benign versus malignant thyroid nodules, there were differences in sensitivity and specificity rates. ChatGPT 4.0 exhibited higher sensitivity rates, particularly in the image-to-text approach, making it potentially more effective in identifying true positive cases. However, Gemini showed higher specificity, indicating a better ability to correctly identify true negative cases.
- Incorporating radiologist expertise and AI Integration. Noting that one senior reader exhibited higher sensitivity, accuracy and specificity with the human-LLM model in comparison to the image-to-text capability of Gemini, the study authors emphasized the importance of radiologist experience. Based on some of the study findings, the researchers also noted that LLMs may play a role in improving the diagnostic consistency of radiologists with less experience.
The CNN model did offer a higher AUC (88 percent) as well as higher accuracy (89 percent vs. 84 percent and 82 percent) and specificity rates (81 percent) than image-to-text approaches with ChatGPT 4.0 and Gemini.
However, noting similar sensitivity between ChatGPT’s image-to-text approach and the CNN model (95 percent), the study authors suggested that LLMs offer an enhanced transparency into diagnostic decisions that may bolster the consistency of less experienced radiologists.
“Particularly beneficial for junior doctors, using LLMs enhances symptom recognition and diagnosis understanding, representing a promising avenue for incorporating artificial intelligence into medical diagnosis,” posited Wang and colleagues.
(Editor’s note: For related content, see “Can ChatGPT and Bard Bolster Decision-Making for Cancer Screening in Radiology?,” “Pediatric Thyroid Nodules on Ultrasound: Deep Learning Model and TI-RADS Show Higher Sensitivity than Radiologist Assessment” and “CT Update: FDA Changes Course on Post-ICM Thyroid Monitoring in Young Children.”)
In regard to study limitations, the researchers acknowledged that assessment of the complex analysis capabilities of the LLMs included in the study may have been limited given that diagnosis with those models was geared to TI-RADS with limited signs. The study authors also conceded that the adopted voting mechanism may not provide an accurate assessment of the error rate.



 Technology Provide a Viable Alternative to X-Rays for Aortic Procedures?")