|Articles|January 6, 2003
Continuous speech recognition system scores hit in Japan
An efficient reporting system is a necessity in any PACS environment to provide timely, accurate reports to referring physicians. One high-performance Japanese speech recognition solution was presented in an infoRAD exhibit at the recent RSNA meeting.
Advertisement
An efficient reporting system is a necessity in any PACS environment to provide timely, accurate reports to referring physicians. One high-performance Japanese speech recognition solution was presented in an infoRAD exhibit at the recent RSNA meeting.
AmiVoice from Advanced Media of Tokyo provides continuous speech recognition with a 30,000-word radiological lexicon. The system features speaker independence, meaning users are not required to enroll their voices. Users can dictate reports immediately without first training the system to their voice, the speaker adaptation restriction peculiar to most other speech recognition systems.
Most current voice recognition technologies are based on discrete word recognition, which requires users to remember recognition words, inhibiting their natural speech. AmiVoice allows users to speak naturally, at any speed. According to the exhibit, AmiVoice successfully recognizes any given word at a rate exceeding 95%.
The system allows radiologists to choose typing, transcription, or speech recognition for report generation.
"With speech recognition, we are able to create reports in times equivalent to transcriber and hand operation," said Dr. Hidefumi Fujisawa, of the radiology department of Showa University Northern Yokohama Hospital. "Since the system is available 24 hours a day, seven days a week, we are also able to reduce transcriber costs."
One recent paper (Nippon Acta Radiologica 2002;62:23-36) compared 10 Japanese radiological reports created by two radiologists using conventional typing and the AmiVoice system. Neither had any special training in continuous speech recognition systems.
Total speech input time (56.2 sec) was nearly three times faster than the conventional typing input time (142.8 sec). Word misrecognition occurred in 40 of 1362 words (97.1% rate of accuracy of recognition). The average speech recognition time per report was 31.3 sec, with an additional 25.0 sec required for corrections.
The paper concluded that continuous speech recognition is faster than typing, even considering the additional time required for corrections, and is acceptable in view of the overall reduction in report turnaround time.
AmiVoice was released in 1999 and developed jointly with Pittsburgh-based ISI. It is based on ISI's speech recognition engine designed by Alexander Waibel, Ph.D., director of the Interactive Systems Laboratories at Carnegie Mellon University and a leading expert on speech recognition technology.
Advertisement
Related Content
Advertisement













Advertisement
Advertisement
Trending on Diagnostic Imaging
1
Molecular Imaging in Focus: SNMMI: Can a New Total Body PET Scanner Slash Scan Times and Bolster Sensitivity?
2
Radiology Roundup of FDA News: June 1 — June 7
3
Diagnostic Imaging’s Weekly Scan: May 31 — June 6
4
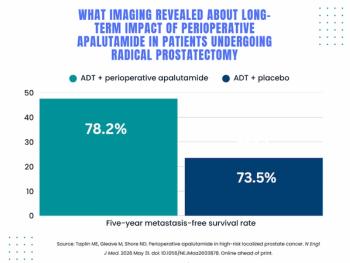
FDA Clears AI Software for Automated Contouring in Radiation Oncology
5