
|Articles|January 10, 2020
Multiphase CT with Deep Learning Accurately Differentiates Small Renal Masses
Author(s)Whitney J. Palmer
Deep learning with a convolutional neural network can support better differentiation of small solid renal masses.
Advertisement
Small solid kidney masses can be adequately differentiated for diagnosis on dynamic CT images by using a deep learning method with a convolutional neural network (CNN), according to new research.
Currently, diagnosis with dynamic CT has depended largely on radiologist experience. This study shows automated image analysis of these masses with deep learning can discern between benign and malignant tumors without requiring a radiologist to have significant experience.
The findings were published in an ahead-of-print issue of
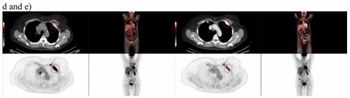
Researchers from Okayama University in Japan studied 168 pathologically diagnosed small solid masses (less than 4cm) from 159 patients between 2012 and 2016. They reviewed 1,807 images sets with four CT phases – unenhanced, corticomedullary, nephrogenic, and excretory. Investigators classified masses as malignant (n=136) or benign (n=32), and they divided the dataset into five subsets – four for augmentation and supervised training and one for testing.
Using the Inception-v3 architecture CNN model, a team, led by Takashi Tanaka, Okayama assistant professor, evaluated the AUC for malignancy and accuracy at optimal cutoff values with six different CNN models. They found no significant size difference between malignant and benign lesions.
In addition, they determined the corticomedullary phase AUC value was higher than other phases. Images in this phase also offered the highest accuracy – 88 percent – and multivariate analysis indicated this phase’s CNN model is also a significant malignancy predictor when compared to other CNN models, age, sex, and lesion size.
“The results of this study are not presumed to indicate that the diagnostic performance of CNN models is superior to that of radiologists; rather, the study was designed to show imaging similarity between malignant and benign masses,” according Tanaka. “However, by preparing and adjusting the appropriate images for training, we might be able to create more promising models to support our daily work.”
Advertisement
Related Content
Advertisement










Advertisement
Advertisement
Trending on Diagnostic Imaging
1
Study Suggests FDG-PET Better than CT for Assessing Treatment Response for Metastatic Breast Cancer
2
Mammography Study Suggests AI Can Bolster the Ability of General Radiologists to Detect Breast Cancer
3
A Closer Look at the Evolution and Emerging Insights with Amyloid and Tau PET for Dementia and Alzheimer’s Disease
4
Could an Emerging Ultrasound Device Facilitate More Efficient Vascular Access Workflows?
5